文献解读 | 中药现代化研究前沿:深度学习结合代谢组数据实现中药精准鉴别
 234
234中草药历史悠久,药效物质复杂,不同药物在成分上差异显著,准确识别其种类对于质量控制和临床应用至关重要。代谢组学有能力全面分析中药代谢物,但是中药代谢组数据具有高维度、小样本量和过拟合问题,限制了其在中药识别中的应用。
本研究的目标是开发一个基于深度学习的人工智能系统(HerbMet),利用代谢组数据来准确识别中药,通过深度学习模型有效提取代谢组数据中的区分性特征,并构建一个分类模型,以提高中药识别的效率。
01研究方法
研究采用了一套综合方法来开发一个基于深度学习的中草药识别系统。
研究人员首先收集了包含七种人参药材和三种葛根药材的代谢组数据集,对数据的预处理包括使用链式方程算法填补缺失值,采用Box-Cox算法进行数据标准化以减少不同数据源之间的分布差异,以及通过自适应合成采样方法处理数据不平衡问题,确保数据质量和模型训练的有效性。
研究设计了一个基于1D-ResNet架构的深度学习模型,模型核心是一个多层感知机,负责将提取的特征映射到最终的分类结果,能够从代谢组数据中提取关键特征,并利用多层感知机进行分类。
为提高模型的泛化能力,减少过拟合风险,优化特征选择,研究人员引入了双重dropout正则化模块(DDR),通过在训练过程中增加模型的不确定性,迫使模型学习更加鲁棒的特征,同时结合先验知识和25种不同的特征排序技术,以揭示关键活性成分,识别最具区分力的特征。
02研究结果
研究结果揭示了HerbMet在识别中的卓越性能,在对七种极易混淆的人参药材进行分类的测试中,识别准确度为95.71%,F1分数为95.42%,相比其他已知机器学习和深度学习方法表现优越,尤其应用特征选择技术后,结合先验知识和25种特征排序技术,HerbMet的准确度达到了完美的100%,在与10种流行的机器学习和深度学习算法的比较中,HerbMet在准确度上提升了超过25%,在F1分数上有17%提升,表明HerbMet在处理中药材复杂高维的代谢组数据时,能够有效地提取关键特征并抵抗噪声干扰。
在计算效率方面,系统也展现出了显著优势,在CPU和GPU环境下均能运行,计算成本也更低,在实际应用中更具吸引力。
03研究结论
研究表明,机器学习和深度学习方法在中药识别领域展现出明显优势,展现了高准确度、优越鲁棒性、较低计算成本等特点,提高了处理大量数据的效率,为中药的质控、药理和临床提供了强力支持。
不过该系统需要高质量代谢组学数据、在泛化能力有待验证,同时不可避免伴随模型可解释性问题,但总体而言,HerbMet对中药现代化具有革新意义。
04研究结果展开
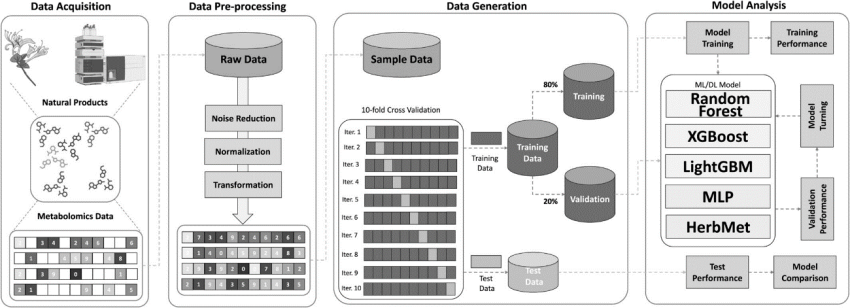
图1.显示了研究总体流程
数据包括了七种人参属根部和三种葛根属种子的代谢组数据,数据经过降噪、标准化和转换等预处理步骤,被随机划分为训练集(80%)、验证集(10%)和测试集(10%),并将HerbMet模型与10种常用的机器学习和深度学习模型进行了对比。
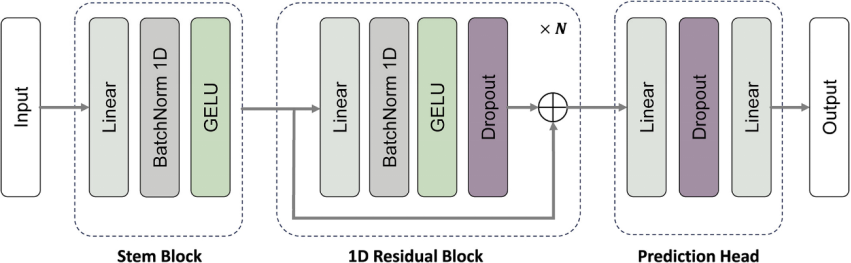
图2.描述了HerbMet系统中的1D ResNet-like结构的架构
这个架构由三个主要部分组成:起始块(stem block),重复N次的一维残差块(1D residual blocks),预测头/输出层(prediction head)。一维残差块结构适合处理序列数据,能够捕捉数据中的长期依赖关系,通过重复的残差块来提取输入样本特征,用来处理分析代谢组学数据,可以提高准确性缓解过拟合问题。
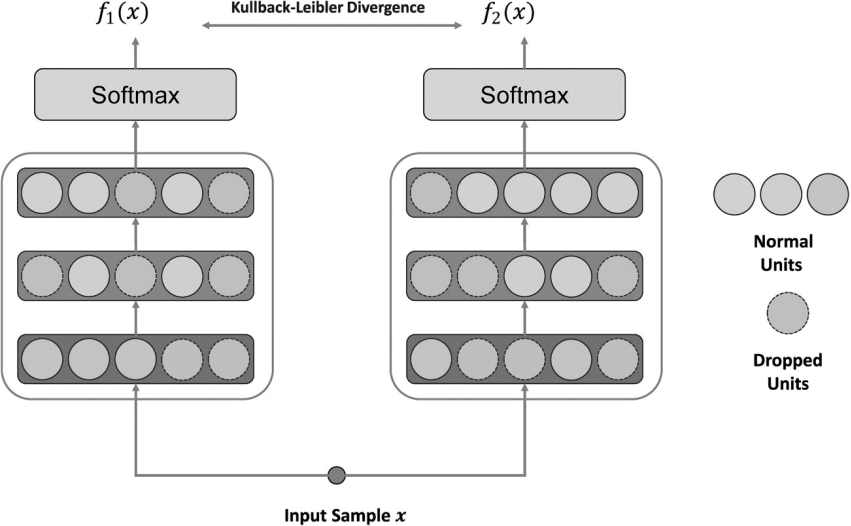
图3.提出了双重正则化模块(DDR)的概念结构,旨在缓解过拟合问题
图中正则化模块由一个‘’丢弃层‘’(dropout layer)组成,在训练过程中应用两次。dropout layer是一种正则化技术,指在训练过程中随机地“丢弃”/暂时移除网络中的一些神经元,以防止模型过拟合。
当输入样本通过神经网络时,它会经历两次前向传递,每次传递中dropout层中丢弃的单元配置都不相同,这导致对同一输入样本产生两个不同的模型预测分布。
f1和f2指的是模型对同一输入样本进行两次前向传播后得到的两次预测分布。DDR的目标是最小化这两个预测分布之间的双向Kullback-Leibler散度,以有效减少过拟合并增强模型的鲁棒性。
(双向Kullback-Leibler散度是一种用于衡量两个概率分布之间差异的度量方法,KL散度越大,差异越大;反之则差异越小,常用于机器学习任务中,训练判别器,以提高模型的稳定性和性能。)
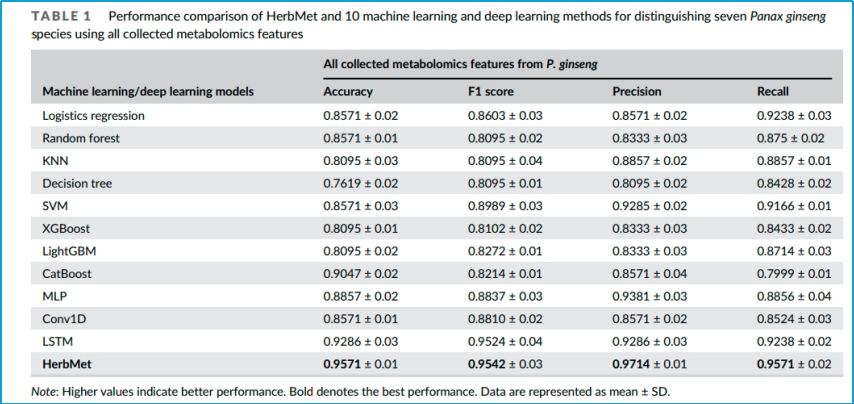
表1.展示HerbMet与其他10种机器学习和深度学习方法在利用代谢组学特征区分中药材人参方面的性能对比表中的性能通过几个关键指标来衡量,包括准确率(Accuracy)、F1分数(F1 score)、精确度(Precision)和召回率(Recall)。准确率表示模型正确预测的样本占总样本的比例;F1分数是精确度和召回率的调和平均数,用于衡量模型的整体性能,特别是在数据集不平衡的情况下;精确度表示被模型正确预测为正类的样本占模型预测为正类的所有样本的比例;召回率表示被模型正确预测为正类的样本占实际为正类的所有样本的比例。表中提到的模型包括Logistic regression(逻辑回归)、Random forest(随机森林)、KNN(K近邻、Decision tree(决策树、SVM(支持向量机)、XGBoost(极端梯度提升)、LightGBM(轻量梯度提升机)、CatBoost(类别增强梯度提升)、MLP(多层感知机)、Conv1D(一维卷积神经网络)、LSTM(长短期记忆网络)、HerbMet(本研究提出的方法)。
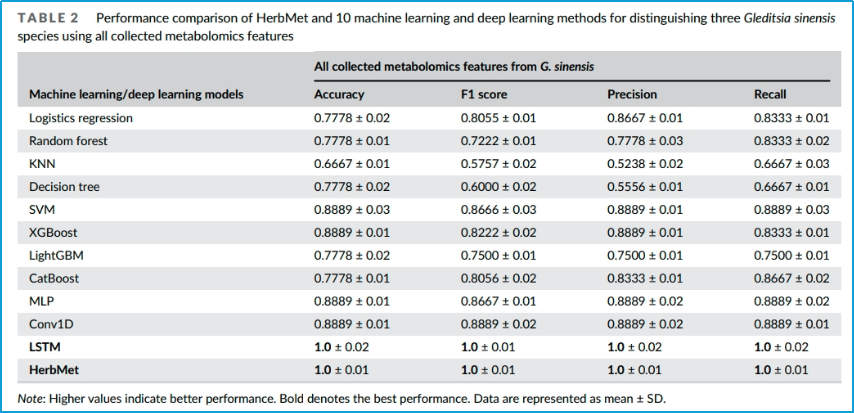
表2.展示了HerbMet与其他10种机器学习和深度学习方法在利用代谢组学特征区分中药材葛根方面的性能对比。
表中的性能指标及各项参数解释参见表1。
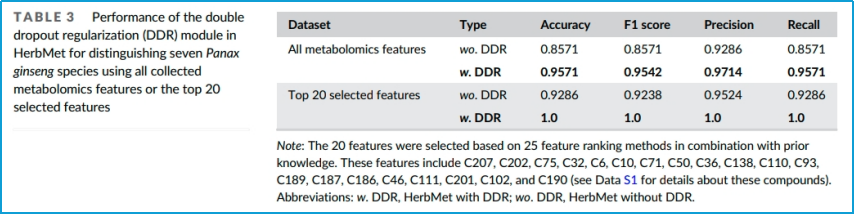
表3.主要描述了在区分人参时,HerbMet模型中DDR模块的性能影响,比较了有无使用DDR模块情况下,HerbMet模型在收集代谢组学特征数据集上的性能比较。
根据表3结果,使用DDR的HerbMet模型在准确率和F1分数上都有显著提升,表明DDR是一个有效的正则化技术,可以提高模型在实际应用中的鲁棒性和可靠性。
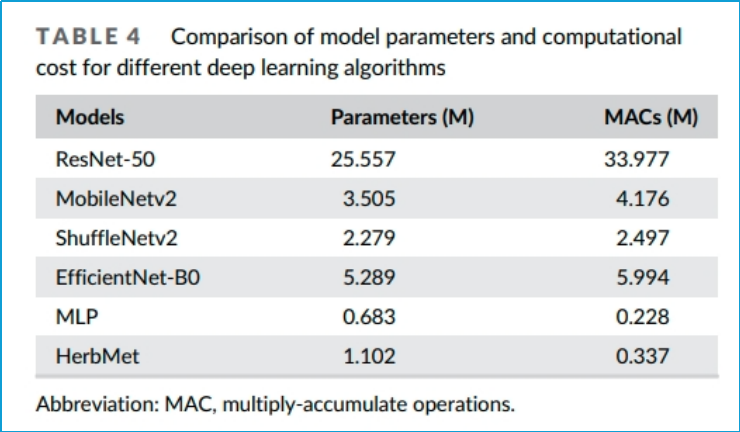
表4.主要描述了不同深度学习算法模型的参数量和计算成本的比较
表中列出了几种不同的深度学习模型,包括ResNet-50、MobileNetv2、ShuffleNetv2、EfficientNet-B0、MLP、HerbMet。参数量(Parameters,M)显示每个模型的参数数量,以百万(M)为单位,一般参数量越多,模型的学习能力越强,但同时也需要更多的计算资源。
乘加操作次数(MACs,M)表示模型在前向传播过程中执行的乘加操作次数,以百万(M)为单位。
乘加操作是深度学习模型中最基本的计算单元,这个指标反映了模型的计算成本和运行效率。这样的比较有助于选择适合需求的模型架构。表5.描述不同机器学习和深度学习方法在CPU和GPU上的推理速度比较
表中比较了单样本和大批量样本(1,000个)输入时的性能(毫秒),反映了模型处理效率。测试所用的硬件配置分别为CPU:Intel Xeon Gold 6338 2.00GHz;GPU:Nvidia GTX 4090。
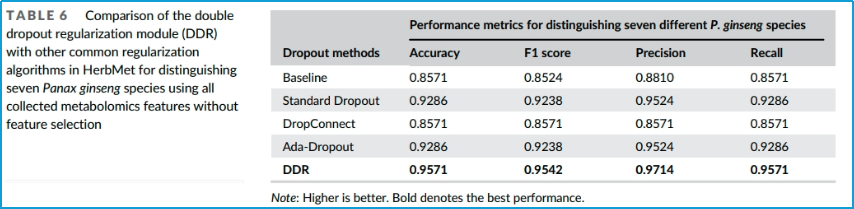
表6.描述HerbMet模型中DDR模块与其他常见正则化算法的性能比较
评价指标包括准确率(Accuracy)和F1分数(F1 score),对比模块包括基线模型,不使用任何正则化方法;标准dropout方法;DropConnect(一种类似于dropout的正则化技术);自适应dropout方法(根据模型在训练过程中的表现动态调整dropout);DDR。
结果表明,DDR在准确率和F1分数上都取得了最好的性能,这表明DDR是一个有效的正则化技术,可以提高模型在实际应用中的鲁棒性和可靠性。
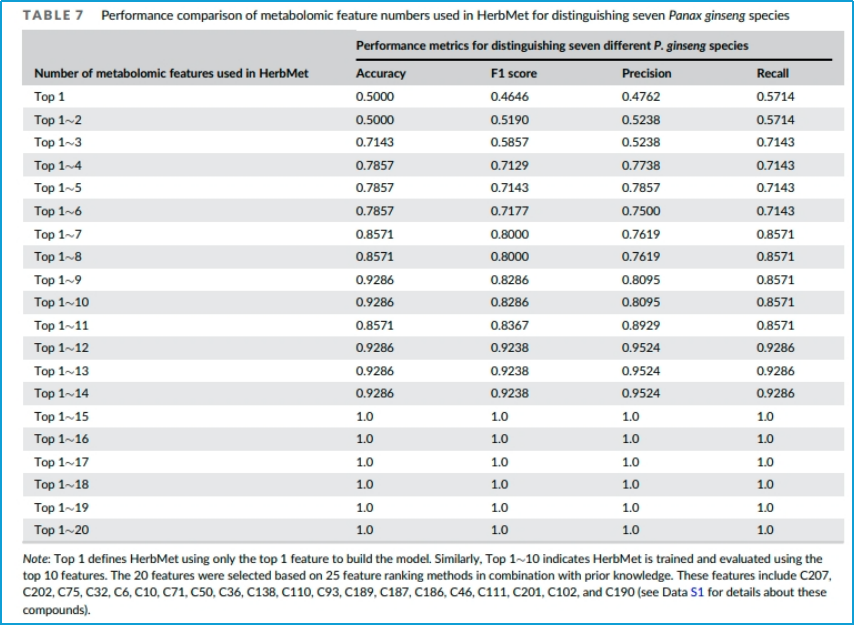
表7.描述在利用HerbMet模型区分中药时,不同数量的代谢组特征对模型性能的影响
表中展示了随着使用的特征数量的增加,模型在准确率(Accuracy)、F1分数(F1 score)、精确度(Precision)和召回率(Recall)这几个性能指标上的变化。
表中的行代表了使用不同数量的代谢组特征来训练和评估HerbMet模型的情况,比如说:Top 1-3表示使用排名最高的前3个特征,准确率达到0.7;Top 1-15表示使用排名前15个特征,准确率达到1。
通过这种方式揭示哪些最重要的特征对提高分类准确性贡献最大,表明可能只需要测量和分析小部分关键代谢物,就能达到高效的物种鉴定目的,从而简化分析流程并降低成本。
05总结与启发
该篇文献发表于Phytochemical Analysis(IF>3),这篇文献提供了一个全新的中药研究现代化的案例,研究团队首先提出了中药鉴定中的挑战,特别是不同物种和品种之间的相似性导致的鉴定难题,并提出了利用深度学习和代谢组学数据分析相结合的创新方法。
在实验设计上,采用了1D-ResNet架构和多层感知机对特征进行提取和分类,并引入了双dropout正则化模块来减少过拟合,提高模型的泛化能力。通过与多种机器学习和深度学习方法的性能比较,研究结果表明HerbMet在中药物种鉴定方面具有显著优势。
研究探讨了特征选择对模型性能的影响,发现通过选择关键特征可以显著提高分类准确性,这有助于简化实际应用中的分析流程并降低成本。研究还提供了模型实现的具体信息,包括优化器选择、学习率调度和训练周期等,以及模型在不同硬件上的推理速度评估,这对于模型的实际部署至关重要。
最后,研究提出了未来工作的方向,包括模型结构的进一步优化、更多数据集的收集以验证模型的泛化能力,以及开发在线平台以便于中药的特征选择、模型训练和物种鉴定。
参考文献
Sha,Y.,Jiang,M.,Luo,G.,Meng,W.,Zhai,X.,Pan,H.,Li,J.,Yan,Y.,Qiao,Y.,Yang,W.,&Li,K.(2024).HerbMet:Enhancing metabolomics data analysis for accurate identification of Chinese herbal medicines using deep learning.Phytochemical Analysis.https://doi.org/10.1002/pca.3437
 上一篇
上一篇
CTI华测检测受邀参与“营养保健食品科普知识进社区”公益活动—虹口曲阳站
10月31日,由上海保健品行业协会、上海市消保委健康消费专业办公室(虹口区消费办)联合主办,上海中药行业协会、上海市虹口区市场监管局协办的以“共建消费诚信 共享健康生活 ”为主题的营养保健食品科普宣传公益活动走进虹口区曲阳社区。
2024-11-18 02:42:18
中国出入境检验检疫协会成立进出口中药材标准化技术委员会
为更好地推动中药材质量提升和发展、传承精华、守正创新,充分发挥标准化工作在满足市场需求和技术创新的引领作用,促进中医药标准和认证的国际互认,加强中医药国际贸易高质量发展,中国出入境检验检疫协会近日批准成立了“中国出入境检验检疫协会进出口中药材标准化技术委员会(CIQA/TC14)”。
2022-07-12 02:50:35
关于印发《按照传统既是食品又是中药材的物质目录管理规定》的通知
根据《中华人民共和国食品安全法》及其实施条例的规定,经商市场监管总局同意,国家卫生健康委制定了《按照传统既是食品又是中药材的物质目录管理规定》。
2021-11-16 18:08:16



 一键下单 流程透明
一键下单 流程透明 专业服务 权威公正
专业服务 权威公正 传递信任 彰显品质
传递信任 彰显品质 根植中国 服务世界
根植中国 服务世界
- 热线电话
- 业务咨询
- 快速询价
- 在线客服
- 报告验证