文献解读 | 中药现代化研究前沿:机器学习结合代谢组学精确评估牛黄质量
 173
173牛黄在中医药领域被广泛使用,其药效被认为具有清热解毒、开窍醒神等功效。由于牛黄的自然形成过程漫长且形成率低,市场上常常出现供不应求的情况,因此,寻找替代品或通过体外培养方式获取牛黄变得尤为重要。然而不同来源的牛黄在成分和药效上可能存在差异,因此评估不同来源牛黄的药品质量至关重要。
本研究旨在开发一种结合代谢组学数据和机器学习算法的高效方法,用于评估其间的化学差异,从而确保牛黄的质量和疗效。
01研究方法
研究收集了自然牛黄(NCB)与体外培养牛黄(IVCB),将自然牛黄(NCB)分为三个等级,从每个等级的样本中筛选出化学标记物,利用这些化学标记物作为特征变量,构建了不同核函数的支持向量机(SVM)模型。
SVM是一种常用的分类算法,适用于处理复杂的模式识别问题。通过使用不同的核函数,模型能够适应不同的数据结构,优化分类性能。
为了确保模型的准确性和泛化能力,将数据集分成多个子集,采用交叉验证方法对SVM模型进行训练和验证,确保每个子集都有机会作为测试集被使用,从而评估模型表现。研究人员利用训练好的SVM模型对NCB样本进行分类,以评估其与IVCB的一致性,将模型的分类准确率作为评估其性能的关键指标。
02研究结果
研究结果显示,支持向量机(SVM)模型对自然牛黄(NCB)样本进行分类,实现了95.74%的高准确率。这一数字表明,模型在区分不同等级的NCB样本方面表现出色,能够有效地将它们与体外培养牛黄(IVCB)进行比较。
在专门针对样本一致性进行的评估中,SVM模型的准确率达到了完美的100.0%,这一结果证实了模型的高度精确性,也反映出在中药质量控制方面的巨大潜力。
具体来说,该模型能够无误差地识别出与IVCB一致的NCB样本,这对于确保药品的标准化和疗效至关重要。研究筛选出的化学标记物,作为特征变量输入到SVM模型中,证明了其在样本分类中的关键作用,这些化学标记物的筛选和应用,不仅提高了模型的预测能力,也为未来中药研究提供了数据支持。
03研究结论
研究成功开发了一种基于组学策略和机器学习算法的高效方法,用于评估不同来源牛黄的一致性,模型达到了95.74%的分类准确率,而一致性评估的准确率更是达到了100.0%,突显了其在中药质量控制领域的应用价值。
研究的现实意义在于,通过这种先进的评估方法,可以确保不同批次或来源的中药在成分和疗效上的一致性,从而保障了中药的安全性和有效性,对于推动中药的标准化和国际化具有重要意义,有助于提升中医药在全球医学领域中的地位和影响力。
04研究结果展开
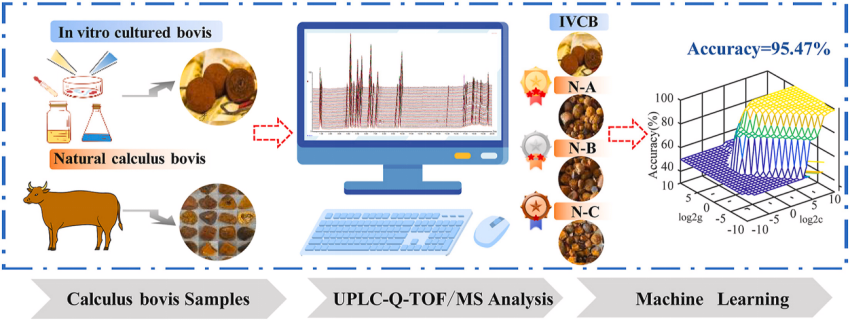
图1.显示了研究总体流程
研究收集了体外培养牛黄(IVCB)与自然牛黄(NCB)开展液相色谱质谱分析,根据化合标志物的不同将NCB分为三类(N-A,N-B,N-C),继而通过机器学习方法对数据集进行分析。
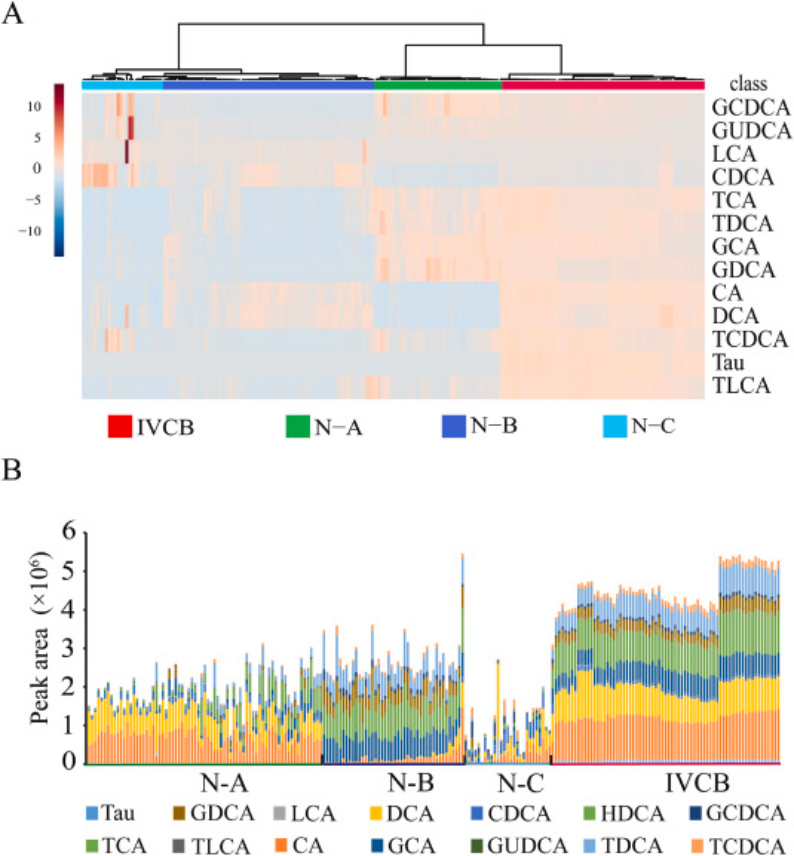
图2.主要描述了牛黄样本的分级情况
A为4种牛黄样本的层次聚类分析,通过这种方法,样本被分成不同的组;
B描绘了每个等级中牛黄样本的相对含量之和,反映出每个组内样本的总体特征。缩写:TUDCA(牛磺去氧胆酸)、GDCA(甘氨去氧胆酸)、CDCA(鹅去氧胆酸)、TDCA(牛磺去氧胆酸)、GCDCA(甘氨鹅去氧胆酸)、CA(胆固醇酸)、TCDCA(牛磺鹅去氧胆酸)、DCA(去氧胆酸)、Tau(牛磺酸)、TCA-Na(牛磺胆酸钠)、TLCA-Na(牛磺石胆酸钠)、UDCA(熊去氧胆酸)。
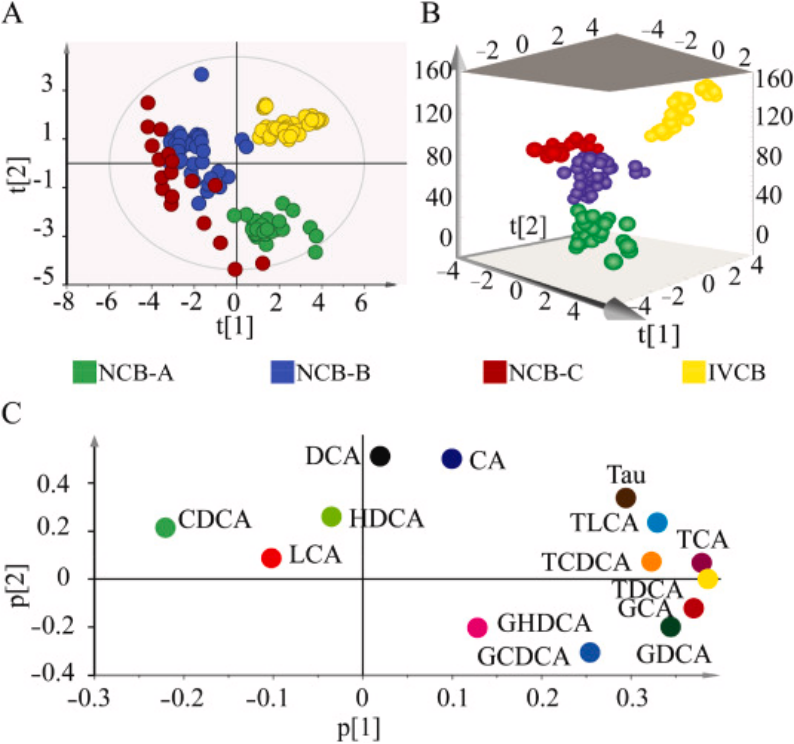
图3.通过主成分分析(PCA)得分图展示不同来源牛黄样本的组间差异
A为平面视图,显示了不同组别牛黄样本在二维空间的分布,便于观察组间差异;B为三维视图,提供了样本在三维空间的立体展示,进一步揭示样本间的关系;C为主成分得分图,描绘了样本在主成分分析中的得分情况,反映了数据的主要变异趋势。
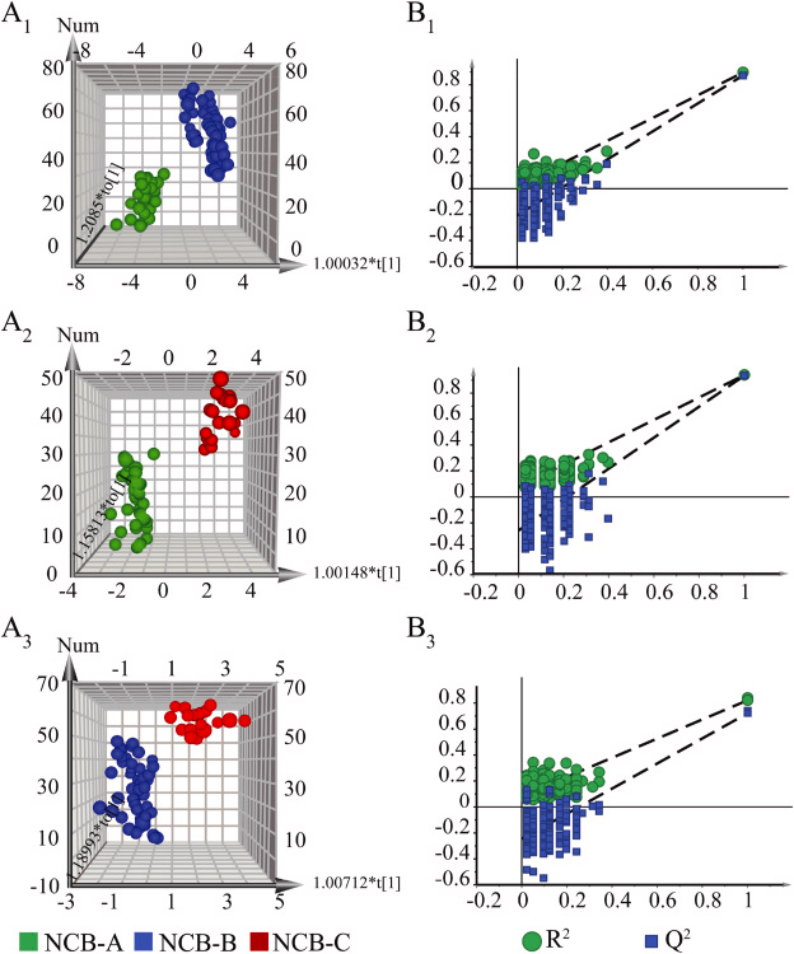
图4.利用正交偏最小二乘分析(OPLS-DA)对自然牛黄(NCB)样本进行了深入分析,并通过三维得分图(A1-A3)展示了不同样本在多维空间的分布情况。
这种三维视图有效地揭示了样本之间的差异和相似性,使得数据的内在结构更加直观和易于理解。同时,通过200次排列测试的验证图(B1-B3),该图展示了模型验证的结果,排列测试通过随机重新分配样本标签来评估模型的稳健性。图中的R²和Q²值等关键统计指标表明了模型的拟合度和预测能力,确保了OPLS-DA分析结果的可靠性。
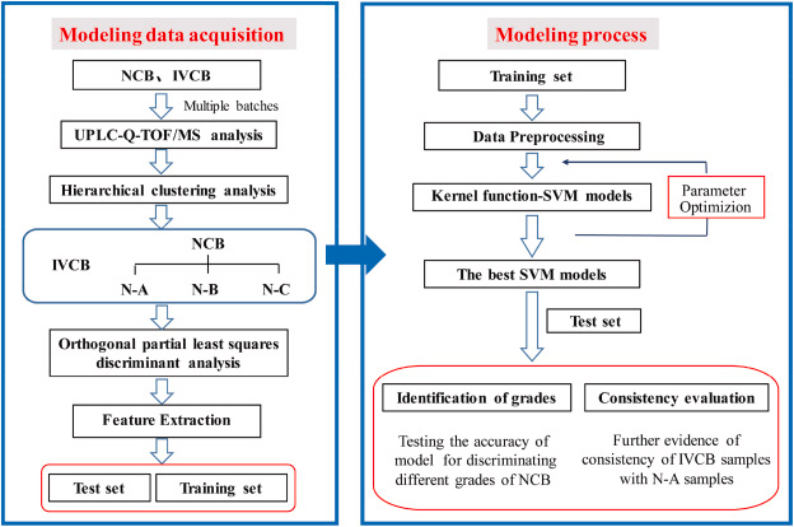
图5.描述课题推进的整个流程
构建过程包含数据获取和建模过程两个部分,数据获取依靠NCB和IVCB的代谢组学分析,以层次聚类分析将NCB样本细分为N-A、N-B和N-C三个亚组,进行正交偏最小二乘判别分析和特征提取,将数据分为训练集和测试集;
建模过程以训练集进行数据预处理,建立核函数-SVM模型并进行参数优化,得到最优SVM模型,并将其用于测试集,最后呈现等级识别和一致性评估结果,等级识别是对模型区分不同等级NCB的能力进行验证,一致性评估是对IVCB样本与N-A样本的一致性进一步验证。
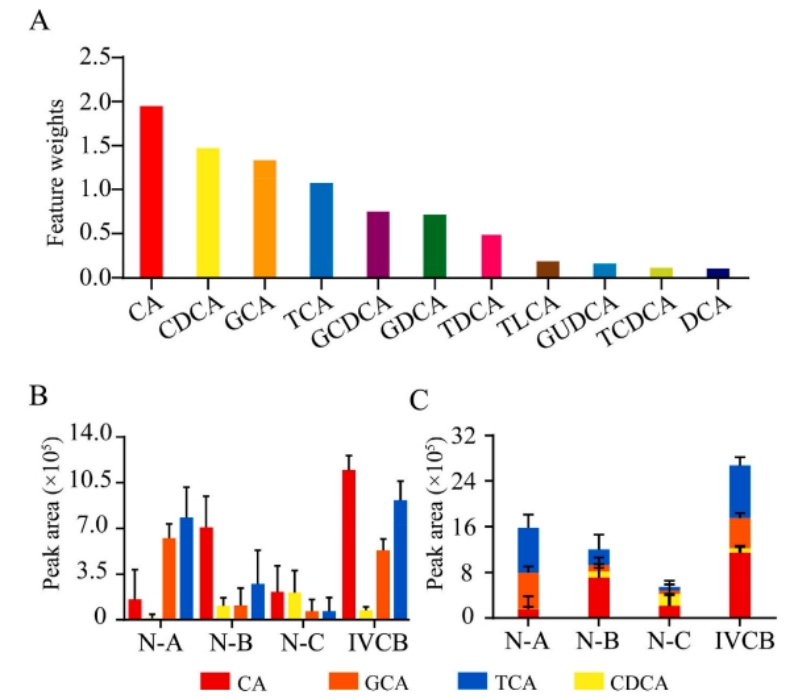
图6.描述不同来源牛黄样本中关键标记物的含量和重要性
A通过最近邻成分分析揭示了每个关键标记物的权重系数,突出显示了它们在样本分类中的作用大小。
B呈现了每组牛黄样本中关键标记物的强度,通过条形图或折线图的形式,使各样本组之间含量的差异一目了然。
C部分利用堆叠直方图详细描绘了每组样本中关键标记物的分布,进一步强调了不同标记物在各组样本中的相对和绝对含量。
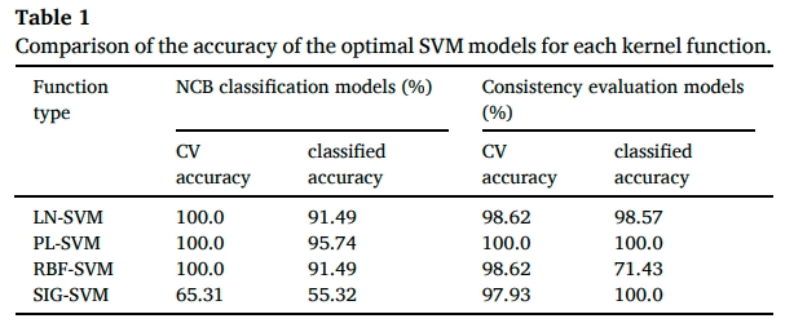
图7.展示了不同类型核函数下最优支持向量机(SVM)模型的分类准确率
表中核函数的类型,包括线性核(Linear)、多项式核(Polynomial)、径向基函数核(RBF)、Sigmoid核;其中两个参数CV accuracy和classified accuracy分别指交叉验证准确率和分类准确率。
05总结与启发
该篇文献发表于Talanta(IF>6),相关内容主要是关于牛黄一致性评估的研究,通过将机器学习技术与组学策略相结合,为中医药从业人员提供了深刻的洞见。
研究中,通过筛选关键化学标记物并应用支持向量机(SVM)模型,实现了对不同来源牛黄样本的高效分类,准确率达到了令人印象深刻的高水平。
这一成果不仅凸显了数据驱动分析在中药质量控制中的应用潜力,也展示了机器学习在提高研究效率和决策科学性方面的重要价值。通过交叉验证和排列测试等严格的模型验证步骤,确保了所得结果的可靠性和模型的泛化能力。
此外,对不同SVM核函数的比较分析进一步证实了选择合适的模型参数对于提升分类性能的重要性。这些发现强调了数据科学在现代科学研究中的核心地位,并为中医药的现代化和国际化提供了新的技术支持。
参考文献
Li,X.,Yao,Y.,Chen,M.,Ding,H.,Liang,C.,Lv,L.,Zhao,H.,Zhou,G.,Luo,Z.,Li,Y.,&Zhang,H.(2022).Comprehensive evaluation integrating omics strategy and machine learning algorithms for consistency of calculus bovis from different sources.Talanta,237,122873.
 上一篇
上一篇
CTI华测检测受邀参与“营养保健食品科普知识进社区”公益活动—虹口曲阳站
10月31日,由上海保健品行业协会、上海市消保委健康消费专业办公室(虹口区消费办)联合主办,上海中药行业协会、上海市虹口区市场监管局协办的以“共建消费诚信 共享健康生活 ”为主题的营养保健食品科普宣传公益活动走进虹口区曲阳社区。
2024-11-18 02:42:18
中国出入境检验检疫协会成立进出口中药材标准化技术委员会
为更好地推动中药材质量提升和发展、传承精华、守正创新,充分发挥标准化工作在满足市场需求和技术创新的引领作用,促进中医药标准和认证的国际互认,加强中医药国际贸易高质量发展,中国出入境检验检疫协会近日批准成立了“中国出入境检验检疫协会进出口中药材标准化技术委员会(CIQA/TC14)”。
2022-07-12 02:50:35
关于印发《按照传统既是食品又是中药材的物质目录管理规定》的通知
根据《中华人民共和国食品安全法》及其实施条例的规定,经商市场监管总局同意,国家卫生健康委制定了《按照传统既是食品又是中药材的物质目录管理规定》。
2021-11-16 18:08:16



 一键下单 流程透明
一键下单 流程透明 专业服务 权威公正
专业服务 权威公正 传递信任 彰显品质
传递信任 彰显品质 根植中国 服务世界
根植中国 服务世界
- 热线电话
- 业务咨询
- 快速询价
- 在线客服
- 报告验证